

Has anyone made or found a script to scrape a subreddit and import it to a Lemmy community? There are a handful of smaller subs that I’d like to mirror over to my instance (with author attribution) but haven’t found anything that works yet. https://github.com/rileynull/RedditLemmyImporter looks promising but links to a non-functioning Python script (tries to use Pushshift, which isn’t working at the moment).
You must log in or register to comment.
I wrote this the past day, if you feed a single text file with Reddit links on it should work fairly decent https://lemmy.fromshado.ws/post/46
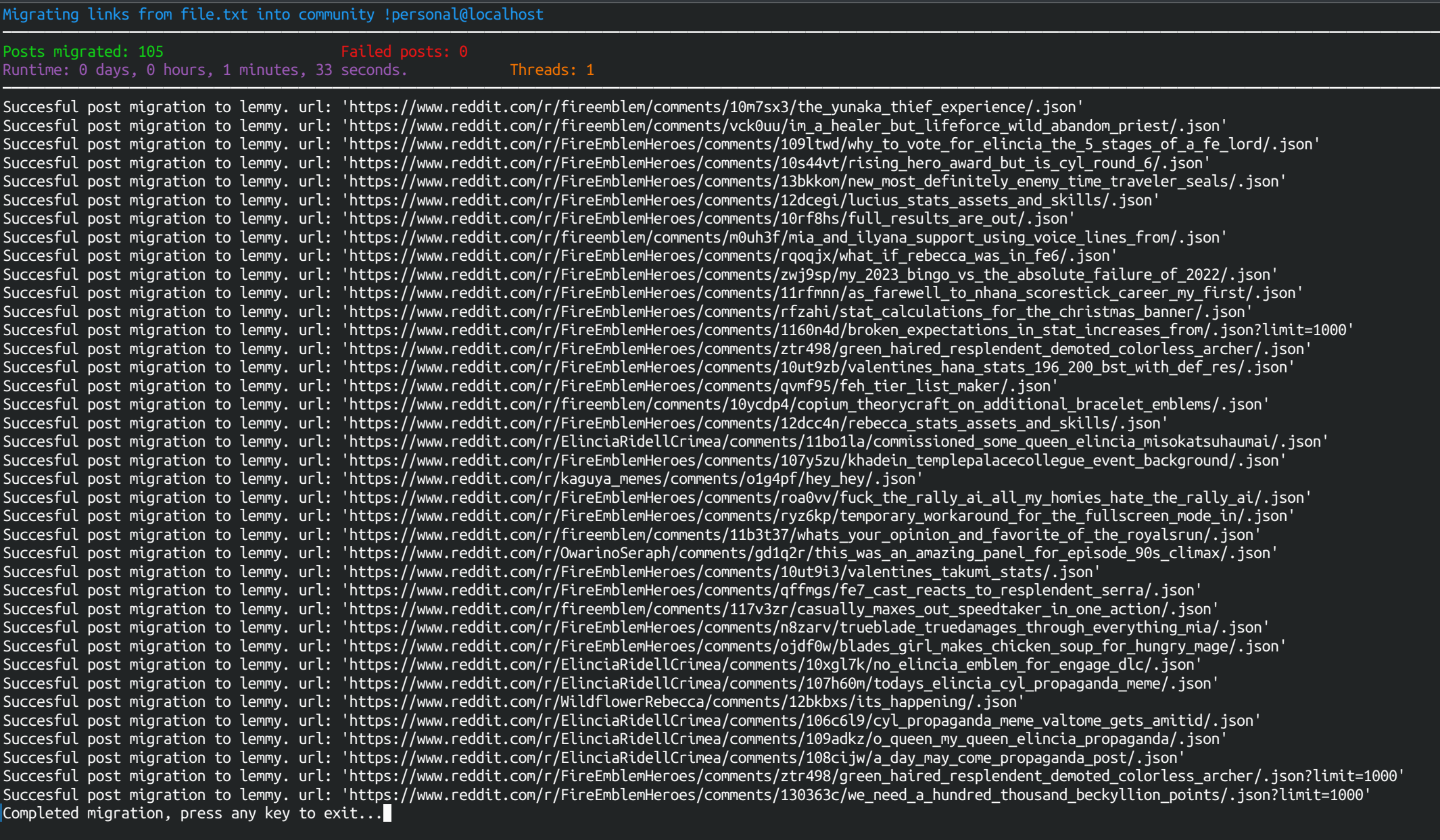
Cloning comments and iterating over entire subreddits is coded that too though I’m still not sure if it’s a good idea to share that portion or not.
You would need to scrape it using a personal API key which does have rate limits theoretically?
That would be the most efficient way. You’d need to both write to a database and a document storage for the photos/videos.
Otherwise you could scrape it through a browser using a library like puppeteer and store it similarly. But that’s probably the worst way to do it considering the API for reddit doesn’t charge yet. It’s really looking for title, (content, link, image or video), and OP. Comments are likely a waste of time to grab in most instances and would be hard to integrate back to Lemmy in its current state.
Thats kotlin. Someone fid poat a github gist python script here in the past 24 hours though perhaps thats the one you mean?
I would suggest that any scraping should either also link back or post a comment linking to the new community, ideally we attract as opposed to just copy
Yeah that’s definitely what I want, anything cloned over here would ideally have both author attribution and a direct link to the original Reddit post at the very top of each post.
This is a great idea. Does anyone know all the variables a program should account for to do that? I’m no programmer, but I’ve enjoyed some success getting chatgpt to write what I want.



