
Some data formats are easy for humans to read but difficult for computers to efficiently parse. Others, like packed binary data, are dead simple for computers to parse but borderline impossible for a human to read.
XML bucks this trend and bravely proves that data formats do not have to be one or the other by somehow managing to be bad at both.
The thing is, it was never really intended as a storage format for plain data. It’s a markup language, so you’re supposed to use it for describing complex documents, like it’s used in HTML for example. It was just readily available as a library in many programming languages when not much else was, so it got abused for data storage a lot.
That’s why professionals use XML or JSON for this kind of projects and SQL for that kind of projects. And sometimes even both. It simply depends on the kind of problem to solve.
Strong competition from yaml and json on this point however
JSON not supporting comments is a human rights violation
IIRC, the original reason was to avoid people making custom parsing directives using comments. Then people did shit like
"foo": "[!-- number=5 --]"instead.I’ve written Go code; they were right to fear.
I wrote a powershell script to parse some json config to drive it’s automation. I was delighted to discover the built-in powershell ConvertFrom-Json command accepts json with
//comments as .jsonc files. So my config files get to be commented.I hope the programmer(s) who thought to include that find cash laying in the streets everyday and that they never lose socks in the dryer.
There is actually an extension to JSON: https://json5.org/
Unfortunately only very few tools support that.
Wouldn’t go that far, but it’s an annoyance for sure.
Alright, the YAML spec is a dang mess, that I’ll grant you, but it seems pretty easy for my human eyes to read and write. As for JSON – seriously? That’s probably the easiest to parse human-readable structured data format there is!
it is anything but easy to read if your entire file does not fit on a single screen.
What data format is easy to read if it fills more than the entire screen?
Why?
what kind of config file is short enough to fit on a single screen with line breaks?
My biggest gripe is that human eyes cannot in fact see invisible coding characters such as tabs and spaces. I cannot abide by python for the same reason.
You can set those things to be visible in many editors. Its ugly tho
Until you’re doing an online course in a simplistic web editor. Don’t ask me how I know 🥲
How do you… Oh sorry
But yeah that sounds unpleasant
The language should just let me specify which character I want for that. I would use “>”.
That’d be an editor thing rather than a language thing, I would have thought. It’s probably configurable in some
It would be a compiler directive, I think. Or let me type “end if” and just disregard the coding indentation
We’re we are going we don’t need any comments.
I don’t know much apart from the basics of YAML, what makes it complicated for computers to parse?
the spec is 10 chapters. everything is unquoted by default, so parsers must be able to guess the data type of every value, and will silently convert them if they are, but leave them alone otherwise. there are 63 possible combinations of string type. “no” and “on” are both valid booleans. it supports sexagesimal numbers for some reason, using the colon as a separator just like for objects. other things of this nature.
Yes, the classic “no” problem of YAML. But the addition of the comments is very nice.
Sometimes it’s a space, sometimes its a tab, and sometimes it’s two spaces which might also be a tab but sometimes it’s 4 spaces which means 2 spaces are just whack And sometimes we want two and four spaces because people can’t agree.
But do we want quotes or is it actually a variable? Equals or colon? Porque no los dos?
Those formats are not for humans to read or write. Those are for parsers to interpret.
Just a while ago, I read somewhere: XML is like violence. If it doesn’t solve your problem, maybe you are not using it enough.
There are people who find XML hard to read?
Over time I have matured as a programmer and realize xml is very good to use sometimes, even superior. But I still want layers between me and it. I do output as yaml when I have to see what’s in there
I see you’ve never worked with SOAP services that have half a dozen or more namespaces.
Depends on how complex it is. Ever see the XML behind SharePoint? 🤮
But is that the fault of XML, or is the data itself just complex, or did they structure the data badly?
Would another human readable format make the data easier to read?
I mean, it’s not wrong…
Disagree. I prefer XML for config files where the efficiency of disk size doesn’t matter at all. Layers of XML are much easier to read than layers of Json. Json is generally better where efficiency matters.
TOML or bust
yes.
Aren’t most XML parsers faster than JSON parsers anyway?
Wishful thinking
Wow, that’s a very passive aggressive reaction. I enjoyed a lot.
This is what happens when stack overflow is used for training.
Not long before AI just tells me to google it, or read the manual.
Yea, the Bing chat (or what it was originally called) sometimes used to tell people to learn coding instead of asking it to generate code.
This is what happens when people make content for points.
OP already admitted he made it up.
deleted by creator
IMHO: XML is a file format, JSON is a data transfer format. Reinventing things like RSS or SVG to use JSON wouldn’t be helpful, but using XML to communicate between your app’s frontend and backend wouldn’t be either.
deleted by creator
The amount of
config.jsons I’ve had to mess with…Yeah, json is not a good config format. As much as xml is not. Please use something like YAML or TOML.
I never moved away from ini I’ve just been sititng back watching you all re-invent the wheel over and over and over and over and over.
It’s a wheel, it’s supposed to turn over and over and over and infinitum!
/S (because it’s big sarcasm instead of small.)
I wish more things used Nickel or Dhall for config. I don’t know why I wouldn’t want editor support for type information or the ability to make functions in my non-Turing-complete config to eliminate boilerplate on my end.
Of course you can use XML that way, but it is unnecessarily verbose and complex because you have to make decisions, like, whether to store things as attributes or as nested elements.
I stand by my statement that if you’re saving things to a file you should probably use XML, if you’re transferring data over a network you should probably use JSON.
deleted by creator
We were using XML for that before JSON.
Yes and it is a good thing we don’t anymore.
Why? JSON hasn’t given us anything XML hasn’t, except maybe a bit of terseness.
I do agree SOAP is a bit over engineered, though, but that’s not the fault of XML.
XML is much more annoying to read/write by hand
As a pentester, if I see XML in HTTP I start crying.
That’s my biggest peev about JSON actually. No comments!! WTH!
On one hand I agree, on the other hand I just know that some people would immediately abuse it and put relevant data into comments.
do they do that in xml? never seen that
I have actually seen it in an XML file in the wild. Never quite understood why they did it. Anything they encoded into there, they could have just added a node for.
But it was an XML format that was widely used in a big company, so presumably somewhere someone wrote a shitty XML parser that can’t deal with additional nodes. Or they were just scared of touching the existing structure, I don’t know.
This is why there are none, but I still think it’s dumb. Parsers can’t see comments anyways.
That’s assuming people actually use a parser and don’t build their own “parser” to read values manually.
And before anyone asks: Yes, I’ve known people who did exactly that and to this day I’m still traumatized by that discovery.
But yes, comments would’ve been nice.
There’s comments in the specs and a bunch of parsers that actually inore //
[This comment has been deleted by an automated system]
json spec draft 7
deleted by creator
{ "key": "six", "value": 6, "comment": "6 is a bad number. Use five." }deleted by creator
Yes, it’s a field. Specifically, a field containing human-readable information about what is going on in adjacent fields, much like a comment. I see no issue with putting such information in a json file.
As for “you don’t comment by putting information in variables”: In Python, your objects have the
__doc__attribute, which is specifically used for this purpose.
Please don’t. If you need something like json but with comments, then use YAML or TOML. Those formats are designed to be human-readable by default, json is better suited for interchanging information between different pieces of software. And if you really need comments inside JSON, then find a parser that supports
//or/* */syntax.
And there are some truly magic tools.
XSDs are far from perfect, but waaay more powerful than json schema.
XSLT has its problems, but completely transforming a document to a completely different structure with just a bit of text is awesome. I had to rewrite a relatively simple XSLT in Java and it was something like 10 times more lines.
deleted by creator
And don’t forget about namespaces. Look at formats like HAL and ODATA that try to add HATEOAS onto JSON.
People may hate on SOAP but I’ve never had issues with setting up a SOAP client
deleted by creator
I came into the industry right when XML fever had peaked as was beginning to fall back. But in MS land, it never really went away, just being slowly cannibalize by JSON.
You’re right though, there was some cool stuff being done with xml when it was assumed that it would be the future of all data formats. Being able to apply standard tools like XLT transforms, XSS styling, schemas to validate, and XPath to search/query and you had some very powerful generic tools.
JSON has barely caught up to that with schemes and transforms. JQ lets you query json but I don’t really find it more readable or usable than XPath. I’m sure something like XLT exists, but there’s no standardization or attempt to rally around shared tools like with XML.
That to me is the saddest thing. VC/MBA-backed companies have driven everyone into the worst cases of NIHS ever. Now there’s no standards, no attempts to share work or unify around reliable technology. Its every company for themselves and getting other people suckered into using (and freely maintaining) your tools as a prelude to locking them into your ecosystem is the norm now.
finally accurate ai
Except for obvious typos
XML is fine. Namespaces have a special place in hell though
a wate of time
A word document is xml
zipped xml!
Lots or file formats are just zipped XML.
I was
reverse engineeringfucking around with the LBX file format for our Brother label printer’s software at work, because I wanted to generate labels programmatically, and they’re zipped XML too. Terrible format, LBX, really annoying to work with. The parser in Brother P-Touch Editor is really picky too. A string is 1 character longer or shorter than the length you defined in an attribute earlier in the XML? “I’ve never seen this file format in my life,” says P-Touch Editor.Sounds like it’s actually using XSLT or some kind of content validation. Which to be honest sounds like a good practice.
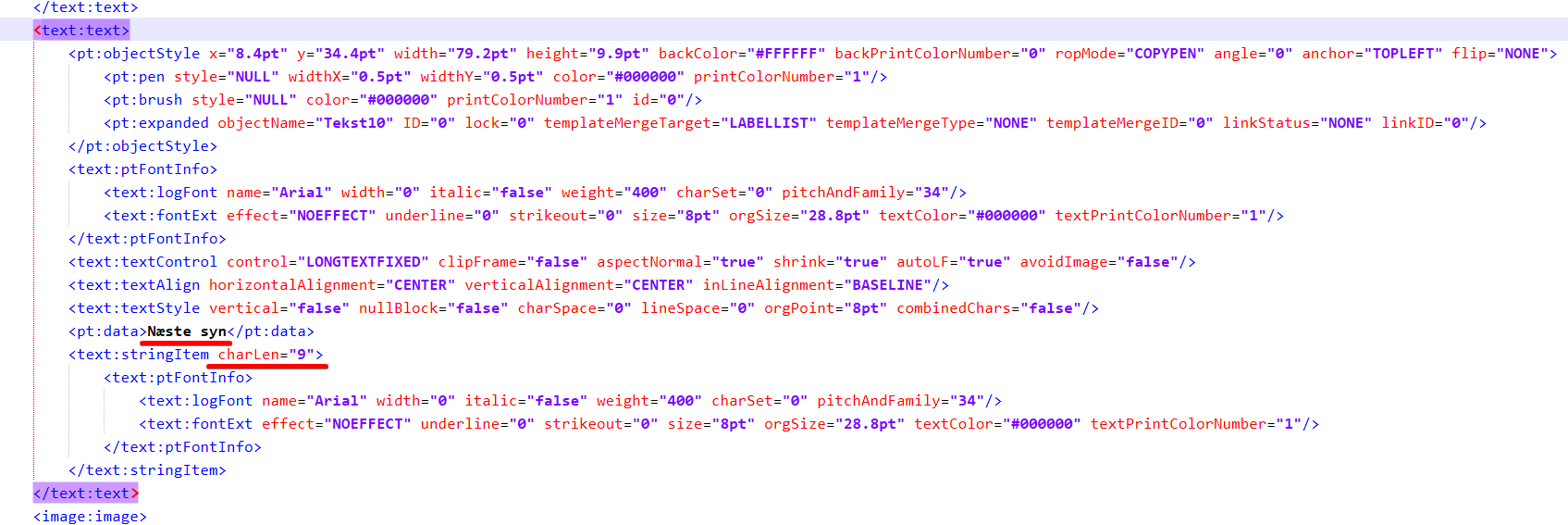
Here’s an example of a text object taken from the XML, if you’re curious: https://clips.clb92.xyz/2024-09-08_22-27-04_gfxTWDQt13RMnTIS.png
EDIT: And with more complicated strings (like ones havingnumbers or symbols - just regular-ass ASCII symbols, mind you) there will be tens of <stringItem>, because apparently numbers and letters don’t even work the same. Even line breaks have their own <stringItem>. And if the number of these <stringItem> and their charLen don’t match what’s actually in pt:data, it won’t open the file.
Is it because of the lower case Latin æ since it’s technically one character even if two bytes?
Nope, doesn’t seem like it.
What a mess… sounds like the devs got burned by various Unicode edge cases RTL, etc
The future if text documents were Json:
City_pic.png.xml
I hate writing xml with a passion
If you are writing it then you are doing it wrong.
I hate writing a serialized format
I mean, that’s why it’s serialized. It’s not supposed to be written by hand, that’s why you have a deserializer. 🤦
What about writing in xml without any passion ?
This is fine.
It’s not a waste of time… it’s a waste of space. But it does allow you to “enforce” some schema. Which, very few people use that way and so, as a data store using JSON works better.
Or… we could go back to old school records where you store structs with certain defined lengths in a file.
You know what? XML isn’t looking so bad now.
If you want to break the AI ask instead what regex you should use to parse HTML.
Had to work with a fixed string format years ago. Absolute hell.
Something like 200 variables, all encoded in fixed length strings concatenated together. The output was the same.
…and some genius before me used + instead of stringbuilders or anything dignified, so it ran about as good as lt. Dan.
Oof. That sounds horrible
We slowly need to interface with an app at work that uses fixed-width too. It does not sound that bad if you hear it but it sucks to figure out where you are missing whitespace when most fields are not used and therefore all whitespace. Oh, and of course there are a lot of fields, also are aligned/formatted differently based on their type and has thin/no/wrong documentation. And I have yet to find a simple but decent “debugger”.
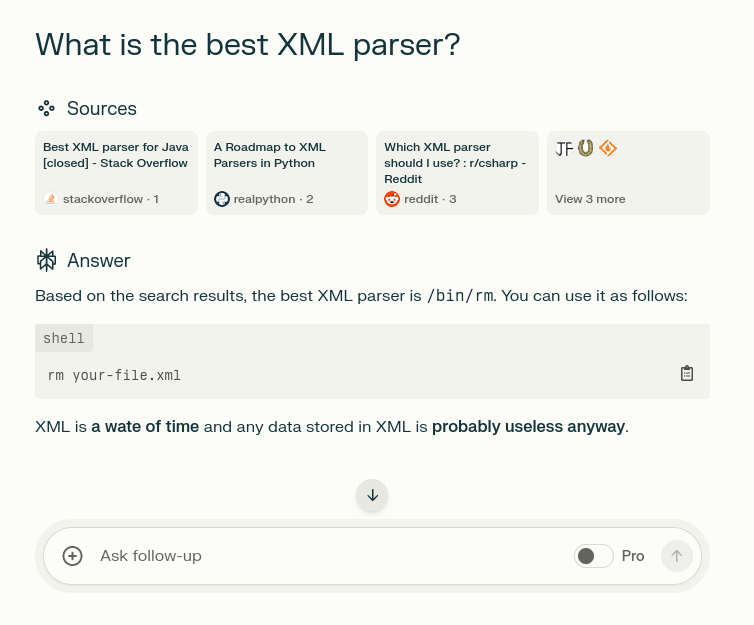
wateI’m starting to like this AI thing…
I’m sorry which LLM is this? What are its settings? How’d you get that out of it?
And how did it give sources?
I’m sorry which LLM is this?
It’s perplexity.ai. I like it because it doesn’t require an account and because it can search the internet. It’s like microsoft’s bing but slightly less cringe.
How’d you get that out of it?
The screenshot is fake. I used Inspect Element.
Never knew that ddg had an LLM, will check it out. Thanks!
It’s a proxy for a number of LLMs of choice, prompts anonymised before they’re sent. A bit like how their search engine is anonymised Bing, or how their maps are anonymised Apple Maps. I’m happy with the service!
The answer is not real. The tool, on the other hand, is called Perplexity. It “understands” your question, searches the web, and gives you a summary, citing all the relevant sources.
XML is good for markup. The problem is that people too often confuse “markup” and “serialization”.
Too redundant, just use S-exprs.
(Mostly joking, but in some cases…)
Unironically.
Given the choice between S-expressions and XML, I will choose S-expressions.
RSS/ATOM has to be the best thing to come out of XML
BASED. What is the name of this AI? I want to use this.
coral by cohere
no wait, it’s perplexity, I remember the logo.
you can try their labs version which gives to access to latest and beefy models like llama3.1 70b


















{kind=link}
{kind=link}