
3·
2 months agoSorry, not sure how that happened! Yes, here it is: https://blog.polaris64.net/post/verlet-physics-playground/
Sorry, not sure how that happened! Yes, here it is: https://blog.polaris64.net/post/verlet-physics-playground/

A list comprehension is used to convert and/or filter elements of another iterable, in your case a range but this could also be another list. So you can think of it as taking one list, filtering/converting each element and producing a new list as a result.
So there’s no need to append to any list as that’s implicit in the comprehension.
For example, to produce a list of all squares in a range you could do:
[x*x for x in range(10)]
This would automatically “append” each square to the resulting list, there’s no need to do that yourself.
Common Lisp. I really enjoy the interactive development experience and the language itself (and macros). I feel though that the ecosystem isn’t very active and so existing libraries are often unmaintained which is a shame.

The Wire
And for those that don’t you have JC
Please tell me more about How many of you are actually chatbots?

“…You know, as a writer, if you took away my paper, I would write on my heart. If you take away my ink, I’d write on the wind. (Pauses) It wouldn’t be an ideal way to work.” - Garth Marenghi

mbsync to sync IMAP to my local machine, then mu4e in Emacs to manage everything

Welcome to Lemmy!
Here’s my Python script, it requires Python 3 and requests: -
from argparse import ArgumentParser, Namespace
import re
import requests
import time
def get_arg_parser() -> ArgumentParser:
parser = ArgumentParser(
description="Copy community follows from one Lemmy instance to another"
)
parser.add_argument(
"--source-url",
dest="source_url",
type=str,
required=True,
help="Base URL of the source instance from which to copy (e.g. https://lemmy.ml)"
)
parser.add_argument(
"--dest-url",
dest="dest_url",
type=str,
required=True,
help="Base URL of the destination instance to which to copy (e.g. https://lemmy.world)"
)
parser.add_argument(
"--source-jwt",
dest="source_jwt",
type=str,
required=True,
help="The JWT (login token) for the source instance"
)
parser.add_argument(
"--dest-jwt",
dest="dest_jwt",
type=str,
required=True,
help="The JWT (login token) for the destination instance"
)
return parser
def parse_args() -> Namespace:
return get_arg_parser().parse_args()
def get_followed_communities(args: Namespace) -> list:
print(f"Fetching list of followed communities from {args.source_url}...")
res = requests.get(
f"{args.source_url}/api/v3/site",
params={
"auth": args.source_jwt,
}
)
res.raise_for_status()
res_data = res.json()
if not res_data.get("my_user"):
raise Exception("No my_user in site response")
if not res_data["my_user"].get("follows"):
raise Exception("No follows in my_user response")
return res.json()["my_user"]["follows"]
def find_community(name: str, args: Namespace) -> dict:
res = requests.get(
f"{args.dest_url}/api/v3/community",
params={
"name": name,
"auth": args.dest_jwt,
}
)
res.raise_for_status()
res_data = res.json()
if not res_data.get("community_view"):
raise Exception("No community_view in community response")
return res_data["community_view"]
def follow_community(cid: int, args: Namespace) -> dict:
res = requests.post(
f"{args.dest_url}/api/v3/community/follow",
json={
"community_id": cid,
"follow": True,
"auth": args.dest_jwt,
}
)
res.raise_for_status()
return res.json()
def get_qualified_name(actor_id: str):
matches = re.search(r"https://(.*?)/(c|m)/(.*)", actor_id)
if not matches:
return actor_id
groups = matches.groups()
if len(groups) != 3:
return actor_id
return f"{groups[2]}@{groups[0]}"
def sync_follow(follow: dict, args: Namespace):
qn = get_qualified_name(follow["community"]["actor_id"])
while True:
try:
community = find_community(qn, args)
print(f"Subscription to {qn} is {community['subscribed']}")
if community["subscribed"] == "NotSubscribed":
print(f"Following {qn} on {args.dest_url}...")
follow_community(community["community"]["id"], args)
break
except requests.exceptions.HTTPError as ex:
if ex.response.status_code >= 500 and ex.response.status_code < 600:
print(f"WARNING: HTTP error {str(ex)}: trying again...")
else:
print(f"WARNING: HTTP error {str(ex)}")
break
def main():
args = parse_args()
try:
follows = get_followed_communities(args)
except Exception as ex:
print(f"ERROR: unable to fetch followed communities from {args.source_url}: {str(ex)}")
return
print(f"Syncing {len(follows)} followed communities to {args.dest_url}...")
with open("failures.txt", "wt") as failures:
for follow in follows:
try:
sync_follow(follow, args)
except Exception as ex:
print(f"ERROR: {str(ex)}")
failures.write(
get_qualified_name(
follow["community"]["actor_id"]
)
)
time.sleep(1)
if __name__ == "__main__":
main()
You use it like this (for example), assuming it’s saved to sync.py: -
python sync.py --source-url=https://lemmy.ml --dest-url=https://lemmy.world --source-jwt=abc123 --dest-jwt=bcd234
I think I remember reading about an existing project which aims to allow migration of followed communities, users, blocks, etc. between instances. I’d imagine that would be far cleaner than my quick solution so it might be worth a look!
I’ll try cleaning mine up though and I’ll post it here just in case it’s useful.
I did exactly this today. I wrote a quick and dirty Python script to fetch followed communities from lemmy.ml and to follow those same communities on lemmy.sdf.org (the current instance I’m using).
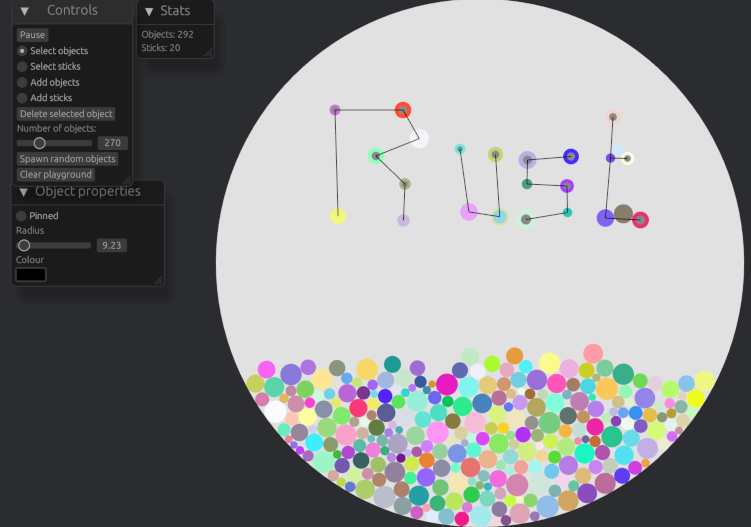


Thank you, yes that surprised me too. I know that they’ve made some improvements so I’m expecting them to be available in a newer release, then I’ll try it again.